 蓝时代
蓝时代
随着人工智能技术的发展,在一些场景的应用也越来越成熟,人工智能正在逐步渗透进人们生活的各个角落,甚至在这次的抗击新冠疫情中也扮演了重要角色。
新技术的应用
对比2003年的非典,此次新冠疫情在症状上潜伏期更长,传染性更强,而且还碰上了流感爆发以及春运流动的节点,因此病情人数不断上升,在防治上面临了更大的困难。
正因如此,在大规模传染之后,现有的医疗资源难以满足不断增长的病患用户。为了实现更好的管控防治效果,提高效率,不少企业纷纷应用诸多技术手段来抗击疫情。比如有些地方推出了智能机器人,通过语音识别、自然语义理解等技术,针对疫情问题、就医注意、防护措施进行回答。对于正常用户、轻症用户来说,人工智能可以起到一定的答疑作用,避免医疗资源紧缺以及交叉感染的风险。
其实,人工智能还被应用于疫苗研发,比如使用深度学习技术,可以协助科研人员进行数据分析、快速筛选文献以及相应的测试工作。此外,人工智能还可以应用于建立模型以观察疫情传播。早前,国内基于AI和大数据的流感实时预测模型便登上了《柳叶刀》的子刊,为传染病预测提供了更加精准的逻辑框架。
神奇的算法
人工智能技术为何能发挥出如此大的作用,魔力的来源究竟是什么?
人工智能在这些年的快速发展主要得益于算力提升、数据积累和算法创新。其中,算法是人工智能的灵魂,是魔力的主要来源,今天我们就一起来看一看这些算法的本来模样。
算法(Algorithm)这个概念比较抽象,是指一个准确而完整的关于解题方案的描述,用系统的方法描述解决问题的策略。简单地说,算法就是解决问题的处理步骤,一个生活中的例子就是我们烹饪的时候往往需要食谱的帮助,食谱描述了美味料理的制作方法,对制作料理这个问题给出了方案,并将操作步骤规范地描述出来。
算法一词来源已久,截止目前,网上不完全统计有2000多个算法,如果考虑到每个算法的各类变种,数量极其巨大。但是这些算法按照模型训练方法的差异,总体上可以分为四个类别:有监督学习(Supervised Learning)、无监督学习(UnsupervisedLearning)、半监督学习(Semi-supervised Learning)和强化学习(Reinforcement Learning)。这些算法是如何让机器具备了“智能”,它们作用的原理是什么?今天,我们尝试用几个样例来揭开背后的秘密。
1、有监督学习
有监督学习被称为“有老师的学习”,所谓的老师就是标签。通过标注好的样本(即训练样本以及其对应的目标)训练得到一个最优模型,再利用这个模型对输入的数据进行判断给出结果,从而具备对未知数据进行预测的能力。
在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。这也比较符合我们的认知习惯,比如我们通过图片或实物学习什么是猫、什么是狗等。
经典的有监督学习算法有:反向传播神经网络、波尔兹曼机、卷积神经网络、多层感知器、循环神经网络、朴素贝叶斯、高斯贝叶斯、多项朴素贝叶斯、分类和回归树、ID3算法、C4.5算法、C5.0算法、随机森林、线性回归、逻辑回归、支持向量机等。
这些专业名称不重要,我们以大名鼎鼎的AlphaGo为例来了解一下有监督学习的原理。从2016年到2017年,这个围棋机器人在多种场合以绝对优势战胜了数十位顶尖的人类棋手。围棋界公认AlphaGo围棋的棋力已经超过人类职业围棋顶尖水平,在GoRatings网站公布的世界职业围棋排名中,其等级分曾超过排名人类第一的棋手。
AlphaGo为了解决围棋的复杂问题,结合了有监督学习和强化学习的优势,通过标注数据训练形成一个策略网络,将棋盘上的当前棋子的布局状态作为输入信息,对所有可能的下一步落子位置生成一个概率分布。以 -1(对手胜利)到1(AlphaGo胜利)为标准,预测所有落子位置的得分。也就是说,针对每个棋盘状态定义了一个学习目标,如此大量的循环往复,模型学会了应对不同的棋盘布局能够预测最佳落子位置,最终取得令人瞩目的成果。
2、无监督学习
无监督学习被称为“没有老师的学习”,相比有监督学习的不同之处在于,不使用事先标注的训练样本,没有训练的过程,而是直接拿无标注的数据进行建模分析,通过机器学习自行学习探索,从数据集中发现和总结模式或者结构。
典型的无监督学习算法包括:生成对抗网络(GAN)、前馈神经网络、逻辑学习机、自组织映射、Apriori算法、Eclat算法、DBSCAN算法、期望最大化、模糊聚类、k-means算法等。
这里以k-means算法为例来看看无监督学习背后的运行机制,这是一种用来计算数据聚类的算法。

例如,对上图中的A、B、C、D、E五个点聚类,主要方法是不断地设定并调整种子点的位置,计算离种子点最近的均值,最终根据距离聚成群。灰色的是开始时设定的种子点,首先,计算五个点与种子点之间直接的距离,然后,将种子点逐步移动到点群的中心。最终,A、B、C和D、E分别根据离种子点的距离聚类为点群。
这个方法看上去很简单,但是应用的范围非常广泛,包括给网页文本进行主题分类;分析一个公司的客户分类,对不同的客户使用不同的商业策略;电子商务中分析商品相似度,归类商品,从而得出不同的销售策略等。
曾有人做过一个有趣的分析,给亚洲15支足球队的2005年到2010年的战绩做了一个表,然后用k-Means把球队归类,得出了下面的结果,来,感觉一下是否靠谱?
亚洲一流:日本、韩国、伊朗、沙特;
亚洲二流:乌兹别克斯坦、巴林、朝鲜;
亚洲三流:中国、伊拉克、卡塔尔、阿联酋、泰国、越南、阿曼、印尼。
3、半监督学习
半监督学习,处在有监督学习和无监督学习的中间带,其输入数据的一部分是有标签的,另一部分没有标签,而没标签数据的数量往往远大于有标签数据数量(这也是符合现实情况的)。常见的半监督学习类算法包含:生成模型、低密度分离、基于图形的方法、联合训练等。
4、强化学习
强化学习,主要是让机器从一个状态转变到另一个状态,当完成任务时获得高分奖励,但是没有完成任务时,得到的是低分惩罚,这也是强化学习的核心思想。常见的强化学习类算法包含:Q学习、状态-行动-奖励-状态-行动(SARSA)、DQN、策略梯度算法、基于模型强化学习、时序差分学习等。
强化学习是近些年大家研究的一个重点,我们以Q学习为例说明(此处,引用了McCullock一个非常好的样例)。假设一个房子有五个房间,房间之间通过门连接,从0到4编号,屋外视为一个单独的房间,编号为5,如下方左图。
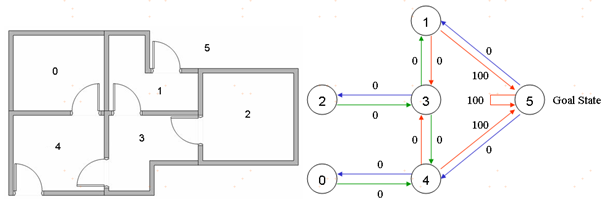
我们把左面的图转换一下,房间作为节点,如果两个房间有门相连,则中间用一条边表示,得到上方右图。
假设我们的目标是从屋内任意一个房间走到屋外,即编号5,2号房间是起点,每条边设定奖励值,指向5的为100,其他为0,可以发现,通过得分奖励,从2到3,再到1或4,最终路线会收敛到5。
相对于以往的算法,强化学习更符合人类学习的习惯,在近年来被寄予了很高的期望,特别是随着DeepMind 和 AlphaGo 的成功,强化学习日益受到关注。
荣光和局限
人工智能技术在这次疫情防控中的应用,离不开大量的算法工作。比如谷歌用AI技术帮助科学家研究病毒特征,亚马逊探索用疫苗等方式来治愈普通感冒等。
当然,人们也不需要把人工智能奉为神明,如果仔细研究一下上文列举的例子就会发现,人工智能擅长处理的是在有限、透明规则、特定任务下的问题,因而在以计算为主要特征的领域取得了不错的效果,但是对于其他问题,比如自然语言理解、图像理解等仍然面临较多的挑战。
文末彩蛋
总有人问,自己不会编程,又对人工智能感兴趣,有没有办法上手呢?
这里介绍一个可视化编程工具Scratch,由麻省理工学院的“终身幼儿园团队”设计开发的图形化编程工具,旨在让初学者不需要学习程序语言便能设计产品。
开发者期望通过使用Scratch,启发和激励用户在愉快的环境下学习程序设计和算法知识,同时获得创造思考、逻辑编程和协同工作的体验。目前最新的版本是Scratch 3.0,采用了HTML5来编写,编辑器的外形看起来更加柔美,拖拽积木还有音效,支持多次撤回和恢复,有兴趣的读者可以试试。
作者 苏宁金融研究院
声明:本文内容和图片仅代表作者观点,不代表蓝时代网立场。蓝时代 » 人工智能助力抗疫,魔力背后的秘密是什么?